Semantic web services
Participants
- Paul
- Luke
- Mark
- Rutger
- Nik
- Martin
- Jessica
- Tom
- Pierre
- José María
- Alberto
- Yulia
- Yunsun
- Bruno
- Toshiaki
Introduction
The holy grail of web service interoperability is hampered along three axes: syntax, semantics and interface. In terms of core data syntax, bioinformatics tools consume and produce data in many different formats, some of which are loosely defined syntactically (e.g. legacy flat file formats). In addition, the semantics of what we are trying to do with data, and what we mean by encoding data in a certain way, are often loosely defined. Many file formats are abused and overloaded to add semantics to fields that weren't intended for that (e.g. in comments, definition lines, key/value fields). Lastly, there is a proliferation of interfaces, each of which probably make sense on their own (e.g. RESTful APIs) but they all aren't interoperable in a way that a machine can make sense of by itself. The semantic web is technically comprised of a stack of common standards and technologies that can be applied to these three axes of syntax, semantics and interface. By adopting these common standards different service providers will be able to promote interoperability.
Why the semantic web?
At a philosophical level, the semantic web enhances science because it forces us to clearly and formally define meanings, intentions and problems. This in turn promotes collaboration, reproducibility and more precise communication. At a technical level, the semantic web makes it easier to get other specialists' data and its computational meaning. Syntax is not enough for this, because syntax can be abused and misinterpreted - true tape safety and end-user usability depends on well-defined semantics. An additional technical benefit is that defining the semantics (i.e. what you mean, what you intend to do), you don't have to hardcode to a particular syntax; hence, web service components become more flexible.
Contributing technologies
The following subsections describe the core technologies that are involved in developing semantic web services (RDF, OWL, SAWSDL).
RDF
RDF assumes that anything in the world can be described in triples, i.e. statements consisting of subject, predicate, object. RDF/XML is just one serialization of the concept of triples (other ways are N3, JSON, RDFa etc.). An RDF/XML document imports at least two namespaces: rdf and rdfs.
Simple example
rdf:Description element defines the subject, rdf:about attribute defines a resource that is the subject. rdfs:label, for example, attaches a human readable label to a subject.
XML representation of RDF:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#">
<rdf:Description rdf:about="http://elmonline.ca/luke">
<rdfs:label>Luke McCarthy's web page</rdfs:label>
</rdf:Description>
</rdf:RDF>
Expanded human-readable representation:
subject: <http://elmonline.ca/luke> predicate: 'rdfs:label' => <http://http://www.w3.org/2000/01/rdf-schema#label> object: "Luke McCarthy's web page"
Condensed human-readable representation:
<http://elmonline.ca/luke> <http://www.w3.org/2000/01/rdf-schema#label> "Luke McCarthy's blog"
Graphical representation: http://elmonline.ca/sw/examples/simpler.png
{kind=link}
Example with more namespaces
subject is now defined on element foaf:Person (again by rdf:about), subject has multiple predicates: foaf:name (his name), foaf:page (which in turn encloses another triple: foaf:Document => dc:title => literal)
XML representation of RDF:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<foaf:Person rdf:about="http://sw.elmonline.ca/elm">
<foaf:name>Luke McCarthy</foaf:name>
<foaf:page>
<foaf:Document rdf:about="http://elmonline.ca/luke">
<dc:title>Luke McCarthy's web page</dc:title>
</foaf:Document>
</foaf:page>
</foaf:Person>
</rdf:RDF>
Condensed human-readable representation:
<http://sw.elmonline.ca/elm> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> . <http://sw.elmonline.ca/elm> <http://xmlns.com/foaf/0.1/name> "Luke McCarthy" . <http://sw.elmonline.ca/elm> <http://xmlns.com/foaf/0.1/page> <http://elmonline.ca/luke> . <http://elmonline.ca/luke> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Document> . <http://elmonline.ca/luke> <http://purl.org/dc/elements/1.1/title> "Luke McCarthy's web page"
Graphical representation: http://elmonline.ca/sw/examples/simple.png
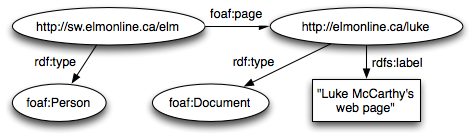{kind=link}
Real example
a set of triples describing Tim Berners-Lee using foaf ( Friend of a Friend), dc ( Dublin core), rss ( Really Simple Syndication), rdfs.
XML representation of RDF:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:rss="http://purl.org/rss/1.0/"
xmlns:html="http://www.w3.org/1999/xhtml">
<foaf:Agent rdf:nodeID="id2246148">
<foaf:name>Tim Berners-Lee</foaf:name>
<foaf:weblog>
<foaf:Document rdf:about="http://dig.csail.mit.edu/breadcrumbs/blog/4">
<dc:title>Tim Berners-Lee</dc:title>
<rdfs:seeAlso>
<rss:channel rdf:about="http://dig.csail.mit.edu/breadcrumbs/blog/feed/4">
<foaf:maker rdf:nodeID="id2246148"/>
<foaf:topic rdf:resource="http://www.w3.org/2001/sw/"/>
<foaf:topic rdf:resource="http://www.w3.org/RDF/"/>
</rss:channel>
</rdfs:seeAlso>
</foaf:Document>
</foaf:weblog>
<foaf:interest rdf:resource="http://www.w3.org/2001/sw/"/>
<foaf:interest rdf:resource="http://www.w3.org/RDF/"/>
</foaf:Agent>
</rdf:RDF>
Condensed human-readable representation:
<id2246148> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Agent> . <id2246148> <http://xmlns.com/foaf/0.1/name> "Tim Berners-Lee" . <id2246148> <http://xmlns.com/foaf/0.1/interest> <http://www.w3.org/RDF/> . <id2246148> <http://xmlns.com/foaf/0.1/interest> <http://www.w3.org/2001/sw/> . <id2246148> <http://xmlns.com/foaf/0.1/weblog> <http://dig.csail.mit.edu/breadcrumbs/blog/4> . # this says that there is an Agent named Tim Berners-Lee who is interested in RDF and the Semantic Web and has a weblog (identified by http://dig.csail.mit.edu/breadcrumbs/blog/4) <http://dig.csail.mit.edu/breadcrumbs/blog/4> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Document> . <http://dig.csail.mit.edu/breadcrumbs/blog/4> <http://purl.org/dc/elements/1.1/title> "Tim Berners-Lee" . # this says that the weblog identified above is a Document titled "Tim Berners-Lee" <http://dig.csail.mit.edu/breadcrumbs/blog/4> <http://www.w3.org/2000/01/rdf-schema#seeAlso> <http://dig.csail.mit.edu/breadcrumbs/blog/feed/4> . <http://dig.csail.mit.edu/breadcrumbs/blog/feed/4> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://purl.org/rss/1.0/channel> . <http://dig.csail.mit.edu/breadcrumbs/blog/feed/4> <http://xmlns.com/foaf/0.1/maker> <id2246148> . <http://dig.csail.mit.edu/breadcrumbs/blog/feed/4> <http://xmlns.com/foaf/0.1/topic> <http://www.w3.org/RDF/> . <http://dig.csail.mit.edu/breadcrumbs/blog/feed/4> <http://xmlns.com/foaf/0.1/topic> <http://www.w3.org/2001/sw/> . # this says that the weblog identified by http://dig.csail.mit.edu/breadcrumbs/blog/4 has an alternative representation (rdfs:seeAlso) that is the RSS feed (rss:channel) identified by http://dig.csail.mit.edu/breadcrumbs/blog/feed/4. This feed is about RDF and the Semantic Web and is written by the Agent above (Tim Berners-Lee)
Graphical representation: http://elmonline.ca/sw/examples/bernerslee.png
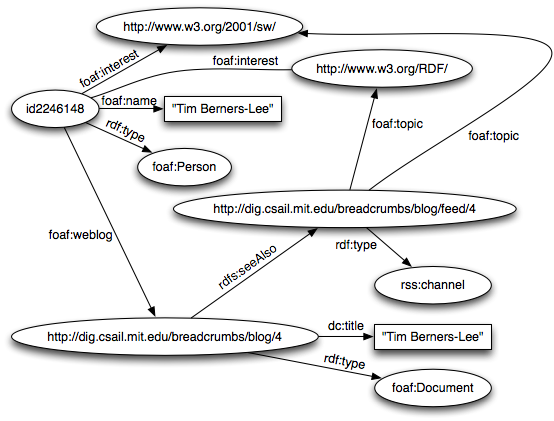{kind=link}
Biological example
a UniProt record: http://www.uniprot.org/uniprot/P47989.rdf
OWL/RDFS
While RDF just defines triples, RDFS(RDF Schema) or OWL (Web Ontology Language) allows for defining classes of things, as opposed to opaque resources, for subjects (class), predicates (property) and objects (class). The previous examples that included things such as foaf:Person were using instances of classes from OWL ontologies.
- Simple example: an OWL ontology that describes a single class defined by duck-typing - anything belongs to CaffeineMetabolismParticipant if its value for isParticipantIn is the KEGG pathway for caffeine metabolism.
SAWSDL
Web services interfaces are described using web service description language ( WSDL). In WSDL documents, semantic web services want to define the semantics of their inputs, outputs and services. This is done using SAWSDL, which provides for the attributes modelReference (which defines the OWL class), liftingSchema (which links to an xslt that lifts the xml syntax into rdf) and loweringSchema (which links to an xslt that converts the rdf back to xml).
Implementing semantic web services
General approach for retro-fitting web services
Assuming you have a web service that consumes and produces xml and that is described using a WSDL, here are the steps you would need to take:
- create a mapping, conceptually, between your xml and relevant owl classes and properties (this involves searching currently published ontologies)
- given that mapping, create xslt style sheets to translate your xml to an rdf/xml instance document and vice versa
- in your wsdl, define how the input and output xml can be lifted to rdf/xml by pointing to the xml=>rdf stylesheet file in the liftingSchema attribute
- also define how the input and output can be lowered from rdf/xml to your xml by pointing to the rdf=>xml stylesheet file in the loweringSchema attribute
- for the simpleTypes and complexTypes in the inputs and outputs, define which owl classes they map onto using the modelReference attribute, which points to a class uri.
Wrapping specific web services
The following points outline our findings when exploring specific web services to wrap to become semantic.
- We decided that WABI services cannot be efficiently wrapped en masse because many (most?) of them output non-standardized, tab-delimited flatfiles; adding semantics into these files would require us to write a special parser for each service, or a semantic transformation grammar - both of which are non-starters from a practical point of view. We suggest that, at a minimum, WABI services should output XML such that we can use generic parsers and generic tools (e.g. XSLT) to add semantics into these services.
- TOGO services are nicer, but don't have a WSDL (because they are RESTful). As such, there is no way for us to wrap them other than one-by-one. Again, unfortunately a non-starter for the scope of the hackathon.
- We have asked Oswaldo to suggest which WABI services he thinks are most interesting/useful for his integration with the Spanish INB, and we will wrap these services during the hackathon as SADI and/or Moby services.
SADI API modifications
The SADI framework is a fully standards compliant reference implementation of semantic web principles applied to health research. The objective of SADI is to make it easy for data and analytical tool providers to quickly make their resources available on the Semantic Web with minimal disruption to their usual practices. The points below enumerate specific modifications the SADI developers identified during the hackathon to interoperate with a larger set of (legacy) service.
- Service provider will "decorate" input by adding a new predicate/object to the incoming data; this is no longer a client-side task
- Client must semantically-type their input data according to the OWL document describing the service provider's input
- this allows the service to find the input nodes based on their rdf:type rather than having to reason-over the incoming data.
- service provider will strip this rdf:type tag off of the data before sending it back to the client.
- Service providers must semantically-type their output data according to the OWL document describing their output such that the client can recognize the nodes that have been decorated by the service. Clients may chose (probably will want to) strip the rdf:type tag off of the returning data.
Semantic Web Services Objectives
- Mark Wilkinson
- Create a list of datatypes representing the core datatypes for the WABI services
- STATUS: DONE by Oswaldo
- Create OWL Classes representing these datatypes
- STATUS: on hold; Oswaldo is mapping to Moby Classes - Mark will map to OWL Classes when he is finished
- José María has just remembered that Dmitry Repchevski (dmitry.repchevski@…) (from INB) did some preliminary work on a Moby => OWL generator.
- Documentation of SADI (This should include movies of the demo's so that people can see it in-action)
- STATUS: Website extensively updated
- Create a list of datatypes representing the core datatypes for the WABI services
- Luke McCarthy
- re-code core SADI code such that services add predicates, rather than client
- Study Paul Gordon's WSDL-2-Moby tool and map some WABI services to BioMoby? for practice
- tweak Paul's WSDL-2-Moby tool to be a WSDL-2-SADI tool
- create some WABI-SADI services
- Paul Gordon
- Finish the WSDL-2-Moby (SAWSDL creation) tool, which still needs to autogenerate the XSLT lifting and lowering schema mappings from the interactive user annotations
- Implement a shared repository for legacy data format transformation rules that jORCA and other projects can use and contribute to, making legacy wrapping simpler
- Solicit users to test the WSDL-2-Moby tools, e.g. legacy WABI and KEGG services can be chained without any programming, just drag and drop
Concerns and limitations
It is unclear how rdf scales, but this is not a priority at the moment.
Resources
Participant projects adopting semantic web technologies
Ontology repositories and search engines
- Standard basic vocabularies
- Ontology repositories
- Other resources
Ontology software tools
Other
Participant projects that may adopt semantic web technologies in the future
- IntAct, EBI, UK - Maybe think on a proposal for the HUPO Proteomics Standards Initiative